ที่มาภาพ: XDA Developers
AI บนเครื่องท้องถิ่นเข้าถึงง่ายขึ้น แต่ VRAM GPU ยังคงเป็นข้อจำกัดหลัก
⚡ สรุป 30 วิ
LM Studio และ Ollama ทำให้การรันโมเดลภาษาใหญ่บนคอมพิวเตอร์ส่วนบุคคลง่ายขึ้นโดยไม่ต้องมีความชำนาญ แม้โมเดล MoE ลดความต้องการ VRAM แต่ขนาด VRAM ของ GPU…
การใช้โมเดลภาษาแบบ Large Language Model (LLM) บนเครื่องคอมพิวเตอร์ส่วนบุคคลเริ่มเป็นไปได้ง่ายขึ้นอย่างเห็นได้ชัดในกลางปี 2026 หลังจากที่ LM Studio และ Ollama ปรับปรุงกระบวนการติดตั้งและการใช้งานให้เหมาะกับผู้ใช้ที่ไม่มีพื้นฐานด้านเทคนิคอย่างมาก การลดช่องว่างระหว่าง AI บนคลาวด์และ AI บนเครื่องท้องถิ่นนี้ทำให้ผู้ใช้ทั่วไปสามารถเลือกใช้ AI แบบท้องถิ่นสำหรับงานประจำวันได้มากขึ้น อย่างไรก็ตาม VRAM ของ GPU ยังคงเป็นปัจจัยสำคัญที่กำหนดประสิทธิภาพและขีดจำกัดของการใช้งาน
Overview
ในช่วงสามปีที่ผ่านมา ความแตกต่างระหว่าง AI บนคลาวด์และ AI บนเครื่องท้องถิ่นยังคงชัดเจนในแง่ของคุณภาพ ความเร็ว และความง่ายในการใช้งาน ผู้ที่สนใจลองใช้ AI แบบท้องถิ่นมักต้องเผชิญกับขั้นตอนการตั้งค่าที่ซับซ้อนและผลลัพธ์ที่ยังไม่เทียบเท่ากับบริการเช่น ChatGPT, Claude หรือ Gemini อย่างไรก็ตาม รายงานของ XDA‑Developers ระบุว่า ณ กลางปี 2026 สถานการณ์นี้ได้เปลี่ยนแปลงไปอย่างมาก
การเปลี่ยนแปลงเกิดจากการพัฒนาซอฟต์แวร์และโมเดลใหม่ที่ลดความต้องการด้านฮาร์ดแวร์ ทำให้ผู้ใช้ที่ไม่มีความชำนาญด้านเทคนิคสามารถติดตั้งและรันโมเดลภาษาได้ด้วยขั้นตอนไม่กี่ขั้นตอน การเข้าถึง AI แบบท้องถิ่นจึงไม่จำเป็นต้องผ่านกระบวนการปรับแต่งระดับลึกอีกต่อไป
Lowering the Barrier
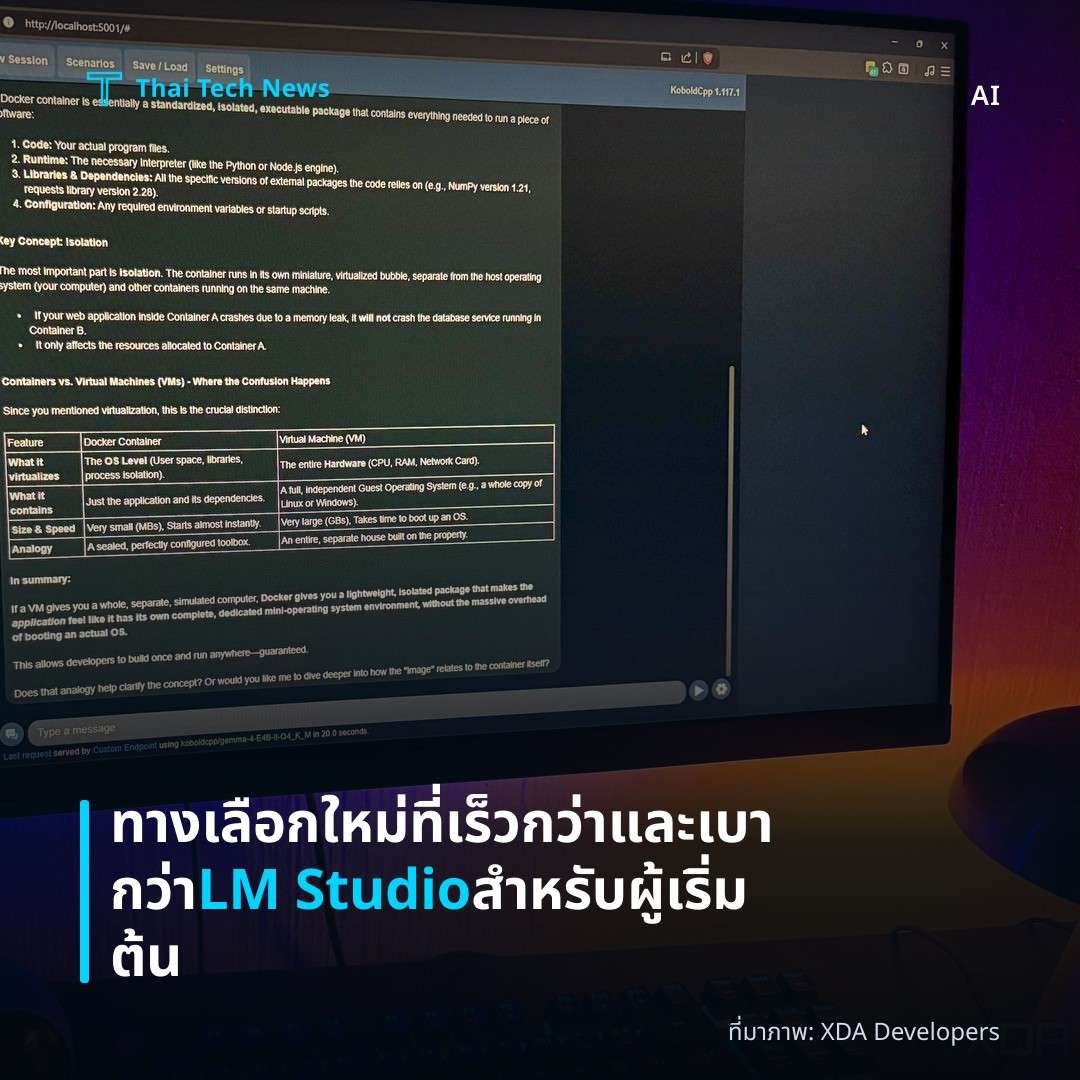
LM Studio และ Ollama เป็นสองแพลตฟอร์มหลักที่ทำให้การใช้งาน AI บนเครื่องส่วนบุคคลเป็นเรื่องง่ายขึ้น ทั้งสองเครื่องมือมาพร้อมกับอินเทอร์เฟซกราฟิกที่ช่วยให้ผู้ใช้เลือกโมเดลที่ต้องการดาวน์โหลดและรันได้โดยไม่ต้องเขียนสคริปต์หรือคอมไพล์โค้ดเอง
นอกจากนี้ แพลตฟอร์มเหล่านี้ยังจัดเตรียมระบบจัดการการดาวน์โหลดโมเดลอัตโนมัติ พร้อมตรวจสอบความเข้ากันได้ของฮาร์ดแวร์และทำการปรับค่าพารามิเตอร์เบื้องต้นให้เหมาะสม การทำเช่นนี้ลดขั้นตอนที่ต้องทำด้วยตนเองลงอย่างมีนัยสำคัญและทำให้ผู้ใช้ทั่วไปสามารถเริ่มต้นใช้งานได้ภายในเวลาไม่กี่นาที
Model Quality Gap
ตามบทความของ XDA‑Developers ความแตกต่างด้านคุณภาพระหว่างโมเดล AI บนคลาวด์และโมเดลท้องถิ่นได้ลดลงอย่างชัดเจน โมเดลที่พร้อมใช้งานบน LM Studio และ Ollama มีประสิทธิภาพใกล้เคียงกับเวอร์ชันบนคลาวด์สำหรับงานทั่วไป เช่น การสรุปข้อความ การตอบคำถามแบบสั้น และการช่วยเขียนโค้ด
แม้ว่าโมเดลระดับสูงสุดบนคลาวด์ยังคงมีขนาดใหญ่และมีความแม่นยำที่เหนือกว่าในบางกรณี แต่การใช้งานในชีวิตประจำวันของผู้ใช้ส่วนใหญ่ไม่จำเป็นต้องพึ่งพาโมเดลเหล่านั้น การเลือกใช้ AI บนเครื่องจึงเป็นตัวเลือกที่คุ้มค่ามากขึ้นโดยไม่ต้องพึ่งพาการเชื่อมต่ออินเทอร์เน็ตที่ต่อเนื่อง
Hardware Evolution & MoE
หนึ่งในปัจจัยสำคัญที่ทำให้ AI บนเครื่องเข้าถึงได้ง่ายขึ้นคือการพัฒนาโมเดลประเภท **Mixture‑of‑experts (MoE) โมเดล MoE แบ่งการทำงานเป็นหลาย “expert” ที่ทำงานร่วมกันและสามารถเลือกใช้เพียงบางส่วนของโมเดลในแต่ละรอบการประมวลผล ทำให้ความต้องการหน่วยความจำกราฟิก (VRAM) ลดลงอย่างมีนัยสำคัญ
ด้วยเทคโนโลยี MoE ผู้ใช้ที่มีการ์ดจอระดับกลาง เช่น NVIDIA GTX 1660 หรือ AMD Radeon RX 5600 ก็สามารถรันโมเดลภาษาได้โดยไม่มีปัญหาที่ชัดเจน ทั้งนี้ระบบยังสามารถสเกลอัตโนมัติตามขนาด VRAM ที่มีอยู่เพื่อให้ได้ประสิทธิภาพที่เหมาะสมที่สุด
Remaining Constraints
แม้ว่าโมเดล MoE จะลดความต้องการด้าน VRAM ลงได้มาก แต่ VRAM ยังเป็นตัวกำหนดหลัก ว่าโมเดลจะทำงานได้เต็มประสิทธิภาพหรือไม่ หาก GPU มี VRAM น้อยกว่าขนาดที่โมเดลต้องการ การทำงานอาจชะลอตัวหรือจำเป็นต้องใช้เทคนิคการสลับส่วนของโมเดล (off‑loading) ซึ่งอาจเพิ่มความซับซ้อนให้กับผู้ใช้
ดังนั้น ผู้ใช้ที่ต้องการประสบการณ์ AI ที่ราบรื่นและรวดเร็วควรตรวจสอบสเปคของ GPU ของตนก่อนทำการติดตั้ง โดยเฉพาะอย่างยิ่งสำหรับงานที่ต้องประมวลผลข้อความยาวหรือทำการสรุปหลายเอกสารพร้อมกัน การอัปเกรด GPU หรือเพิ่ม VRAM ยังคงเป็นทางเลือกที่ดีที่สุดสำหรับผู้ที่ต้องการประสิทธิภาพระดับสูง
Impact
การทำให้ AI บนเครื่องส่วนบุคคลเข้าถึงได้ง่ายขึ้นมีผลกระทบหลายด้าน ทั้งด้านความเป็นส่วนตัว การประหยัดค่าใช้จ่ายและการลดการพึ่งพาโครงสร้างพื้นฐานคลาวด์ ผู้ใช้สามารถจัดการข้อมูลสำคัญบนเครื่องของตนเองได้โดยไม่ต้องส่งไปยังเซิร์ฟเวอร์ของผู้ให้บริการคลาวด์
นอกจากนี้ การเปิดโอกาสให้ผู้ใช้ทั่วไปทดลองและพัฒนาแอปพลิเคชัน AI ของตนเองอาจเร่งการสร้างสรรค์นวัตกรรมในระดับท้องถิ่นและส่งเสริมการแข่งขันในตลาดเทคโนโลยี AI อย่างไรก็ตาม ความต้องการฮาร์ดแวร์ที่เหมาะสมยังคงเป็นข้อจำกัดที่ต้องพิจารณาเพื่อให้การรับมือกับความต้องการที่เพิ่มขึ้นเป็นไปอย่างราบรื่น
Summary
AI บนเครื่องส่วนบุคคลในปี 2026 สามารถเข้าถึงได้ง่ายขึ้นอย่างมากด้วย LM Studio, Ollama และโมเดล MoE ที่ลดความต้องการ VRAM อย่างชัดเจน แม้จะมีความก้าวหน้าแล้ว VRAM ของ GPU ยังคงเป็นปัจจัยหลักที่กำหนดประสิทธิภาพของการใช้งาน AI แบบท้องถิ่น.
แชร์บทความนี้:
ชอบบทความแบบนี้?
สมัคร AI Automate Weekly Newsletter — รับเคล็ดลับ AI + how-to ใหม่
ทุกสัปดาห์ตรงถึง inbox ฟรี ไม่มีสแปม
แหล่งข่าวต้นฉบับ
- ชื่อต้นฉบับ
- Local AI is more accessible than ever, but with one major GPU-sized caveat
- ผู้เขียน
- Tanveer Singh
- แหล่ง
- XDA Developers
- วันที่เผยแพร่
- 17 มิถุนายน 2569 เวลา 19:31